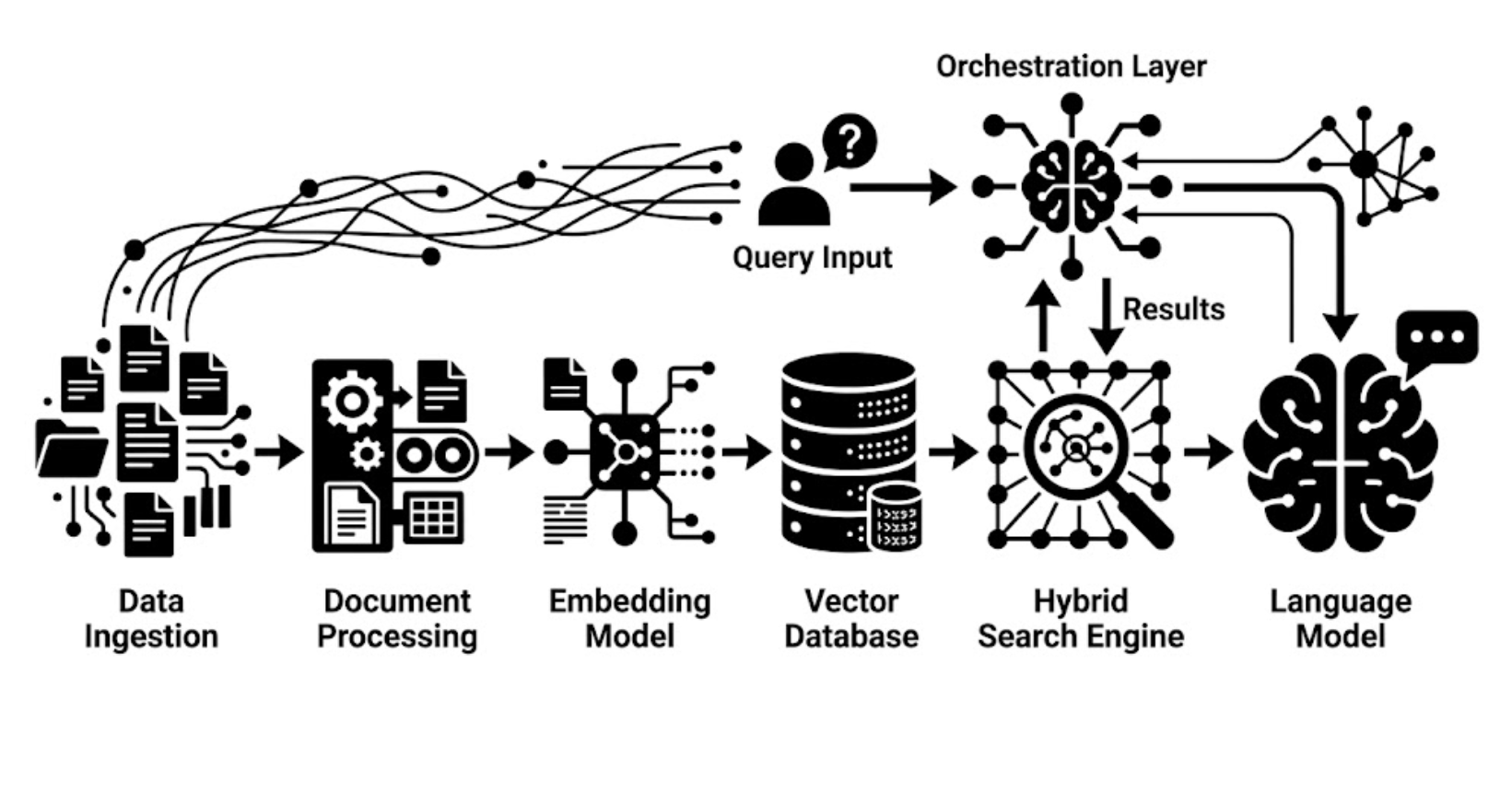
Basic vector search is no longer enough. To build AI systems that don't hallucinate, developers must embrace multi-stage retrieval, entity relationships, and autonomous evaluation. Here is the definitive breakdown of modern Retrieval-Augmented Generation.
1. The Evolution: Why Basic RAG Breaks in Production
Large Language Models are powerful reasoning engines, but their training data is a static snapshot. Standard LLMs hallucinate when asked about proprietary, real-time, or highly niche data. Retrieval-Augmented Generation (RAG) solves this by injecting factual context into the prompt at inference time.
However, Naive RAG (simply chunking text, embedding it, and running a cosine similarity search) fails in real-world scenarios. Vector-only retrieval misses exact keyword matches (like specific UUIDs or acronyms), arbitrary chunk boundaries destroy context, and single-pass retrieval often pulls irrelevant data that confuses the LLM. To achieve high accuracy, we must move to an Advanced RAG architecture.
2. Standard LLM vs. Advanced RAG Architecture
| Capability | Direct LLM Generation | Naive RAG | Advanced RAG (2026 Standard) |
|---|---|---|---|
| Knowledge Source | Static pre-training weights | Basic Vector Database | Hybrid Stores + Knowledge Graphs |
| Data Freshness | Frozen at training cutoff | Updated on batch ingestion | Real-time streaming ingestion |
| Retrieval Mechanism | None (Memory recall) | Dense Vector Similarity (Cosine) | Hybrid (BM25 + Vector) with Reciprocal Rank Fusion (RRF) |
| Reasoning Depth | In-context logic only | Single-hop (direct matches) | Multi-hop (Graph traversal & Agentic planning) |
3. Pre-Retrieval: Intelligent Ingestion & Processing
The quality of your generation is bottlenecked by the quality of your ingestion. Dumping raw text into an embedding model is an anti-pattern.
- Parent-Child Chunking: Instead of retrieving large, noisy chunks, index small "child" chunks (like a single sentence) for highly precise search. When a match is found, pass the larger "parent" chunk (the whole paragraph) to the LLM to provide the surrounding context.
- Metadata Enrichment: Before embedding, use a smaller, faster LLM to extract metadata (date, author, category, sentiment) from the chunk. This allows you to apply hard SQL-like filters before doing a vector search, drastically reducing the search space.
4. The Retrieval Wars: Hybrid, GraphRAG, and Agentic RAG
Retrieval is no longer a single step. The industry has diverged into several highly effective patterns for finding the right data.
A. Hybrid Search
Relying solely on embeddings means you might miss a document that contains the exact serial number the user typed. Hybrid search runs a dense vector search (for semantic meaning) alongside a sparse keyword search (like BM25). The results are mathematically merged using algorithms like Reciprocal Rank Fusion (RRF).
B. GraphRAG vs. Agentic RAG
When dealing with complex, multi-part questions, developers usually choose between these two advanced paradigms:
| Feature | GraphRAG (Knowledge Graphs) | Agentic RAG (Autonomous Routing) |
|---|---|---|
| Core Mechanism | Extracts entities and relationships into a graph database (e.g., Neo4j). Retrieves data by traversing connected nodes. | Uses an LLM as a reasoning agent to dynamically plan queries, select tools, and self-correct based on initial results. |
| Best Used For | Multi-hop reasoning ("How is the CEO of Company A connected to the subsidiary of Company B?"). High completeness. | Vague or multi-part questions requiring different strategies. Open-ended discovery and adaptive retrieval. |
| Trade-offs | High indexing cost. Requires excellent entity-extraction models. Rigid schema. | High latency at inference time. Requires strong orchestrators. Risk of agent loops. |
5. Post-Retrieval: Reranking and Distillation
Once you have retrieved the top 20 documents from your hybrid or graph search, passing all of them to the LLM will bloat the context window, increase costs, and trigger the "Lost in the Middle" phenomenon (where LLMs ignore data in the center of a prompt).
Cross-Encoder Reranking: A specialized model evaluates the user's query against each retrieved document simultaneously. It scores them on true relevance, bubbling the absolute best 3-5 documents to the top before they hit the generation prompt.
6. Evaluation: RAGAS and TruLens
You cannot improve what you cannot measure. "Vibe checking" a RAG system is dangerous. Modern pipelines use LLM-as-a-judge frameworks to calculate metrics automatically based on the RAG Triad:
- Context Relevance: Did the retrieval engine find useful information, or is it garbage?
- Groundedness (Faithfulness): Are the claims made by the LLM strictly supported by the retrieved context, or did it hallucinate details?
- Answer Relevance: Does the final output actually answer the user's original query?
Tools like TruLens utilize a strict 4-point Likert scale to evaluate this triad, excelling at tracking experiments over time. Alternatively, RAGAS uses dual-judge averaging and is incredibly powerful for generating synthetic test datasets directly from your documents—saving hundreds of hours of manual QA.
7. Infrastructure & Tooling: Bringing it Together
Writing raw Python scripts for every pipeline becomes unmaintainable. The modern architect relies on specialized infrastructure:
- Orchestration: Platforms like Dify provide visual control over agentic logic, prompt chains, and memory management.
- Workflow Automation: For data ingestion, tools like n8n, Make, or Activepieces are ideal for connecting to disparate APIs, chunking the data, and syncing it to your databases automatically.
- Search Engines: Rather than duct-taping a vector database to a traditional database, unified engines like Elasticsearch or PostgreSQL (with pgvector) offer robust, out-of-the-box hybrid search capabilities.
- Deployment: Self-hosting these entire stacks on a Linux/Ubuntu server via Docker ensures total data privacy and eliminates per-seat SaaS costs.